背景
ascii码包含0~127标准ascii码及128~255扩展ascii码,其中很多控制符是不可见字符,有些情况下传输不可见字符不方便。比如一个纯文本协议,二进制中可能会出现被当做控制字符处理的部分。这样引起传输失败。,因此,在网络传输中,经常将字节流在传输时转换为base64编码,base32,base16等可见字符编码格式;
编码原理
base64
1、字符表中的字符原本用6个bit就可以表示,现在前面添加2个0,变为8个bit,会造成一定的浪费。因此,Base64编码之后的文本,要比原文大约三分之一。
2、为什么使用3个字节一组呢?因为6和8的最小公倍数为24,三个字节正好24个二进制位,每6个bit位一组,恰好能够分为4组。
base64 编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途。
| 0 | A | 16 | Q | 32 | g | 48 | w |
| 1 | B | 17 | R | 33 | h | 49 | x |
| 2 | C | 18 | S | 34 | i | 50 | y |
| 3 | D | 19 | T | 35 | j | 51 | z |
| 4 | E | 20 | U | 36 | k | 52 | 0 |
| 5 | F | 21 | V | 37 | l | 53 | 1 |
| 6 | G | 22 | W | 38 | m | 54 | 2 |
| 7 | H | 23 | X | 39 | n | 55 | 3 |
| 8 | I | 24 | Y | 40 | o | 56 | 4 |
| 9 | J | 25 | Z | 41 | p | 57 | 5 |
| 10 | K | 26 | a | 42 | q | 58 | 6 |
| 11 | L | 27 | b | 43 | r | 59 | 7 |
| 12 | M | 28 | c | 44 | s | 60 | 8 |
| 13 | N | 29 | d | 45 | t | 61 | 9 |
| 14 | O | 30 | e | 46 | u | 62 | + |
| 15 | P | 31 | f | 47 | v | 63 | / |
示例说明

第一步:“M”、“a”、”n”对应的ASCII码值分别为77,97,110,对应的二进制值是01001101、01100001、01101110。如图第二三行所示,由此组成一个24位的二进制字符串。
第二步:如图红色框,将24位每6位二进制位一组分成四组。
第三步:在上面每一组前面补两个0,扩展成32个二进制位,此时变为四个字节:00010011、00010110、00000101、00101110。分别对应的值(Base64编码索引)为:19、22、5、46。
第四步:用上面的值在Base64编码表中进行查找,分别对应:T、W、F、u。因此“Man”Base64编码之后就变为:TWFu。
位数不足情况
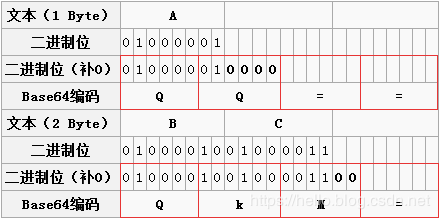
两个字节:两个字节共16个二进制位,依旧按照规则进行分组。此时总共16个二进制位,每6个一组,则第三组缺少2位,用0补齐,得到三个Base64编码,第四组完全没有数据则用“=”补上。因此,上图中“BC”转换之后为“QKM=”;
一个字节:一个字节共8个二进制位,依旧按照规则进行分组。此时共8个二进制位,每6个一组,则第二组缺少4位,用0补齐,得到两个Base64编码,而后面两组没有对应数据,都用“=”补上。因此,上图中“A”转换之后为“QQ==”;
Base32编码
是使用32个可打印字符(字母A-Z和数字2-7)对任意字节数据进行编码的方案,编码后的字符串不用区分大小写并排除了容易混淆的字符,可以方便地由人类使用并由计算机处理。
| 0 | A | 8 | I | 16 | Q | 24 | Y |
| 1 | B | 9 | J | 17 | R | 25 | Z |
| 2 | C | 10 | K | 18 | S | 26 | 2 |
| 3 | D | 11 | L | 19 | T | 27 | 3 |
| 4 | E | 12 | M | 20 | U | 28 | 4 |
| 5 | F | 13 | N | 21 | V | 29 | 5 |
| 6 | G | 14 | O | 22 | W | 30 | 6 |
| 7 | H | 15 | P | 23 | X | 31 | 7 |
| 填充 | = |
Base32将任意字符串按照字节进行切分,并将每个字节对应的二进制值(不足8比特高位补0)串联起来,按照5比特一组进行切分,并将每组二进制值转换成十进制来对应32个可打印字符中的一个。
由于数据的二进制传输是按照8比特一组进行(即一个字节),因此Base32按5比特切分的二进制数据必须是40比特的倍数(5和8的最小公倍数)。例如输入单字节字符“%”,它对应的二进制值是“100101”,前面补两个0变成“00100101”(二进制值不足8比特的都要在高位加0直到8比特),从左侧开始按照5比特切分成两组:“00100”和“101”,后一组不足5比特,则在末尾填充0直到5比特,变成“00100”和“10100”,这两组二进制数分别转换成十进制数,通过上述表格即可找到其对应的可打印字符“E”和“U”,但是这里只用到两组共10比特,还差30比特达到40比特,按照5比特一组还需6组,则在末尾填充6个“=”。填充“=”符号的作用是方便一些程序的标准化运行,大多数情况下不添加也无关紧要,而且,在URL中使用时必须去掉“=”符号。
与Base64相比,Base32具有许多优点:
- 适合不区分大小写的文件系统,更利于人类口语交流或记忆。
- 结果可以用作文件名,因为它不包含路径分隔符 “/”等符号。(这里可以作为编码解码数据文件,创建新文件等)
- 排除了视觉上容易混淆的字符,因此可以准确的人工录入。(例如,RFC4648符号集忽略了数字“1”、“8”和“0”,因为它们可能与字母“I”,“B”和“O”混淆)。
- 排除填充符号“=”的结果可以包含在URL中,而不编码任何字符。
Base32也比Base16有优势:
- Base32比Base16占用的空间更小。(1000比特数据Base32需要200个字符,而Base16则为250个字符)
Base32的缺点:
- Base32比Base64多占用大约20%的空间。因为Base32使用8个ASCII字符去编码原数据中的5个字节数据,而Base64是使用4个ASCII字符去编码原数据中的3个字节数据。
识别
base64包含大小写字母、数字及+/号,base32则只有大写字母与数字2,3,4,5,6,7